
The AI Usage Governance Platform for Scaling Profitably
The profit-protection firewall for AI SaaS. Enforce usage limits, protect margins — without ever proxying user traffic.
Fine-grained Control. Zero surprises.
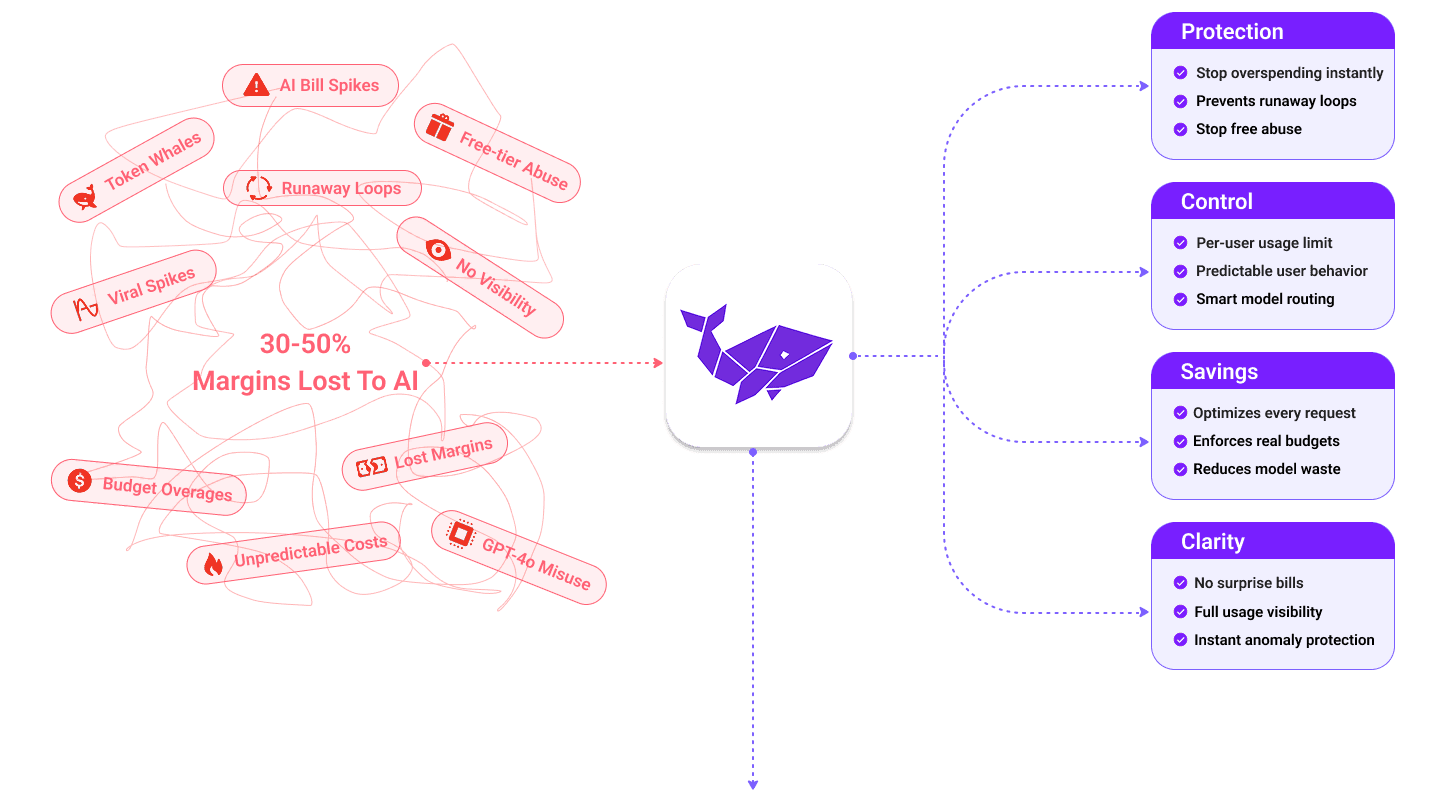
The Six Profit Killers in AI SaaS
If your margins are unpredictable, one of these problems is silently burning your budget. Sound familiar?
Unpredictable costs
Runaway loops, viral users, long PDFs, retries, and spikes can triple your bill with no warning.
Free tier and trials that drain more than they earn
Free-tier and trial users regularly consume 20-40% of total usage and often abuse AI features.
No visibility into true costs
You don't know which users, features, or plans are draining money. Everything is scattered across logs, dashboards, and provider consoles.
Multi-tenant chaos
High-consumption "noisy tenants" burn disproportionate resources, yet you lack the granular controls needed to cap usage without negatively impacting standard customer experience.
Missing User-Level Budget Enforcement
Provider caps are blunt: they only apply to your master account. This prevents you from setting and enforcing practical usage limits per user, feature, or plan tier before a blowup occurs.
Silent Cost Multiplication from Model Misuse
Small application mistakes, bad defaults, or simple user choices are routing traffic to expensive models unnecessarily, leading to hidden, recurring costs that are difficult to track and contain.
Tallywhale gives you real control
Outcomes, not complexity. No gateway required.
Per-user token caps
Set strict limits to prevent any single user from draining your entire monthly budget.
Feature-Level Budgeting
Pinpoint which product features are profitable and which are silently burning cash.
Tiered Model Access
Automatically restrict expensive LLMs based on user plan (Free users stay cheap).
Auto-downgrades for expensive models
Switch GPT-4 to GPT-3.5 automatically when limits are hit. No surprises.
Spike and loop detection
Catch runaway prompts before they rack up hundreds of dollars.
Zero-Proxy integration in 5-15mins
Add one webhook and you're done. Protect margins without routing through a gateway.
Free-tier abuse protection
Block trial users from hammering your AI features.
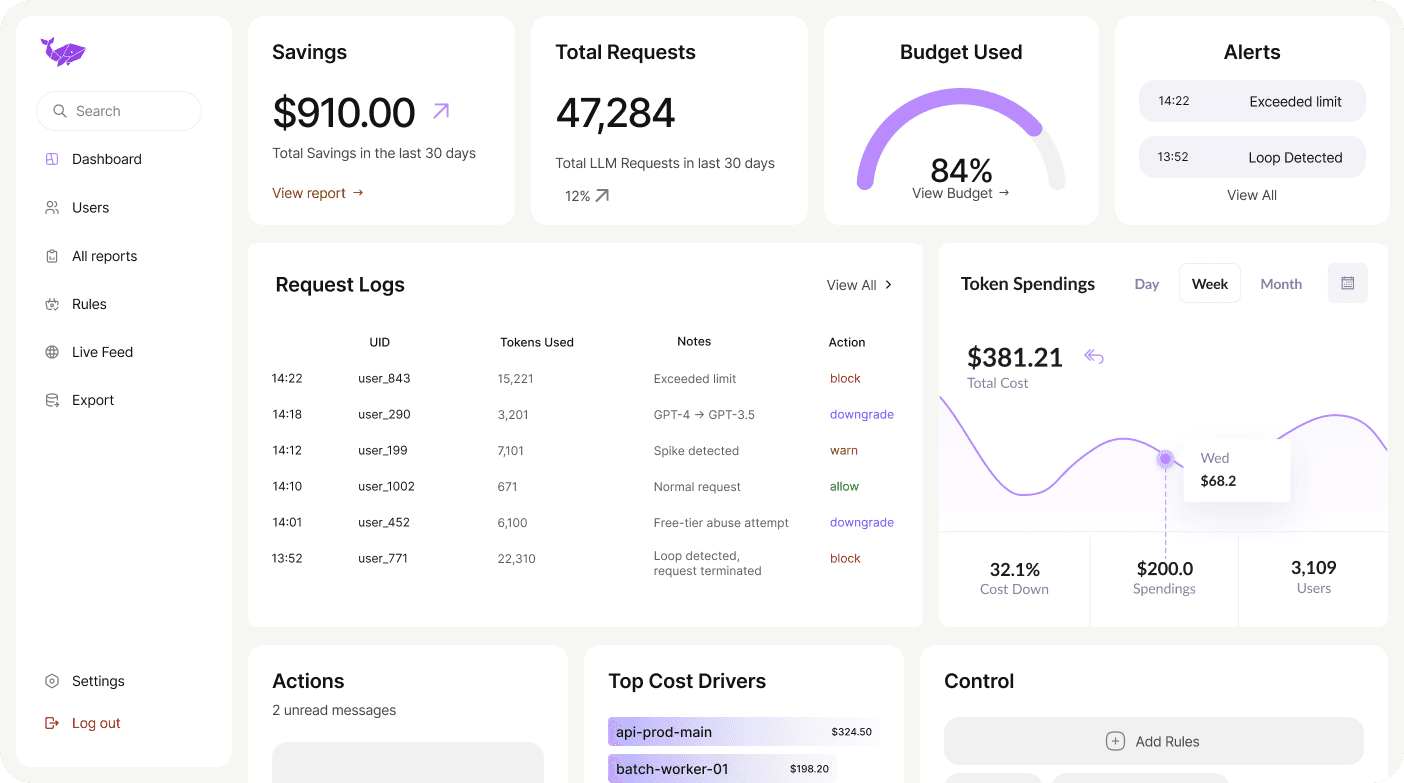
Cost forecasting
See next month's bill before it happens.
Centralized usage analytics
One place to see who's burning tokens and why.
Slack alerts for anomalies
Instant alerts when something goes wrong, not after the bill arrives.
How it works
Your app sends metadata
User, feature, model, estimated tokens.
Tallywhale checks your rules
Plan limits, feature budgets, model restrictions, spike detection.
Tallywhale returns a decision
Allow, block, warn, downgrade.
Your app continues normally
Safe, predictable usage. No surprises.
Ready to stop the bleeding?
Join the waitlist and be the first to know when Tallywhale launches. Early access members get first month free.